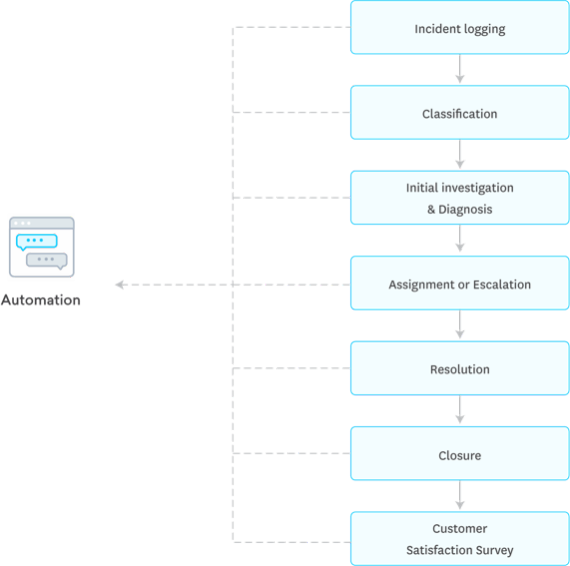
Le flux du processus de gestion des incidents
Le processus de gestion des incidents est composé d'une série d'étapes qui doivent être suivies pour que le processus de gestion des incidents soit efficace.
- Enregistrer l'incident
- Classifier l'incident
- Prioriser l'incident
- Enquête et diagnostic
- Résolution& fermeture de l'incident
Enregistrer l'incident
En matière de gestion des incidents, enregistrer l'incident est la première étape pour signaler un incident identifié. C’est généralement effectué soit par les utilisateurs finaux eux-mêmes au moyen d'une source quelconque de ticket, ou par les agents qui soumettent les tickets pour le compte des utilisateurs finaux. Le modèle de formulaire d'incident est utilisé pour saisir les détails relatifs à l'incident. Ceci accélère le processus de récupération en automatisant sur la base de valeurs. Les canaux qui conviennent sont configurés pour permettre aux utilisateurs de soumettre un ticket. Les canaux courants comprennent l'e-mail, le libre-service et l'application mobile.
Classifier l'incident
La classification des incidents permet de catégoriser les tickets efficacement et de les assigner au bon agent. Les champs catégorie/sous-catégorie sont disponibles dans le modèle du formulaire d'incident afin de choisir la bonne catégorie d'incident associée. Configurez le formulaire d'incident avec la bonne combinaison de champs et automatisez la classification, la priorisation et l'attribution du ticket pour gagner un temps précieux au cours du processus. Une classification des incidents efficace facilite la prise de décisions.
Prioriser l'incident
L'accord sur les niveaux de service (SLA) s'appuie sur la priorité du ticket afin de définir le taux de réponse et de résolution. La priorité décide de la date d'échéance à laquelle le ticket doit être résolu. Il est donc essentiel d'assigner la bonne priorité au ticket. La matrice des priorités recueille l'impact et l'urgence des utilisateurs et décide ensuite de la priorité du ticket. Cela permet de traiter les problèmes critiques à temps. Définissez donc des SLA réalistes afin de satisfaire à vos engagements client.
Enquête & diagnostic
L'équipe de niveau I traite les incidents de faible priorité et les incidents complexes sont traités par les équipes de niveau II et III. L'équipe de niveau I effectue l'analyse et l'enquête initiales. Si aucune résolution n’a été trouvée, l'incident est alors escaladé aux équipes de niveau II et III pour une enquête approfondie. L'incident est associé à l'élément de configuration (CI) concerné pour accélérer le diagnostic.
Résolution & fermeture de l'incident
La résolution de l'incident est cruciale pour satisfaire le SLA et, de ce fait, il est important pour les agents d'obtenir une résolution en temps et en heure pour obtenir un bon niveau de performance. Il est également important de bien communiquer les informations concernant la résolution pour que les utilisateurs puissent revenir à la normale. La fermeture des tickets est traitée automatiquement par le système ou par le biais du portail en libre-service.


