Incident Management Proces
Het Incident Management proces bestaat uit een reeks stappen die moeten worden gevolgd voor een effectief Incident Management proces.
- Incidenten vastleggen
- Incidenten Classificeren
- Incidenten Prioriteren
- Onderzoek en Diagnose
- Incidenten oplossen en afsluiten
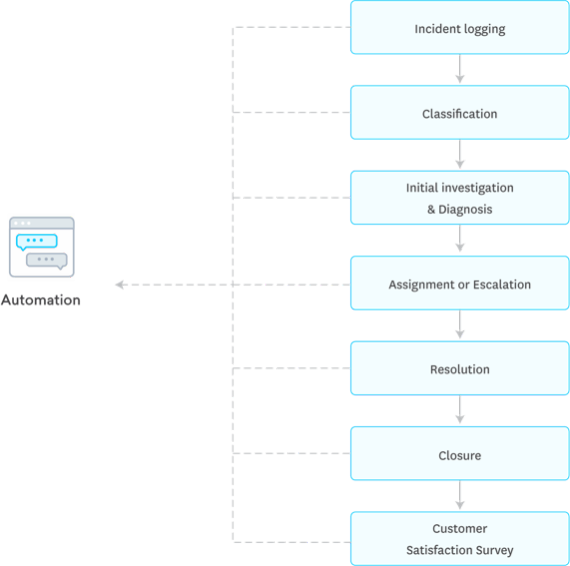
Incidenten Vastleggen
Het vastleggen van incidenten is de eerste stap in incident management om een geïdentificeerd incident te melden. Dit wordt gedaan door eindgebruikers zelf die een ticketbron gebruiken of door agents die tickets indienen namens eindgebruikers. Het Incident-formuliersjabloon wordt gebruikt om details over het probleem vast te leggen. Dit versnelt het herstelproces door te automatiseren op basis van waarden. Relevante kanalen zijn zo geconfigureerd dat gebruikers een ticket kunnen indienen. Veelgebruikte kanalen zijn e-mail, selfservice en mobiele app.
Incidenten Classificeren
Classificatie van incidenten helpt bij het correct categoriseren en toewijzen van tickets aan de juiste agent. Categorie- en subcategorievelden zijn beschikbaar in het sjabloon om de bijbehorende categorie te kiezen. Configureer het incidentformulier met de juiste set velden en automatiseer ticketclassificatie, prioritering en toewijzing om tijd te besparen tijdens het proces. Een juiste classificatie van incidenten helpt bij het nemen van betere beslissingen.
Incidenten Prioriteren
Service Level Agreement (SLA) is afhankelijk van ticketprioriteit om maatstaven voor antwoord en oplossing te definiëren. Prioriteit bepaalt de vervaldatum voordat het ticket moet worden opgelost. Daarom is het essentieel om het ticket de juiste prioriteit te geven. De prioriteitsmatrix verzamelt de impact en urgentie van gebruikers en bepaalt vervolgens de ticketprioriteit. Hiermee worden bedrijfskritieke problemen op tijd aangepakt. Configureer daarom een realistische SLA-definitie om aan de verplichtingen van de klant te voldoen.
Onderzoek & Diagnose
De eerste lijn behandelt incidenten met lage prioriteit en complexe incidenten worden afgehandeld door de tweede en derde lijn. De eerste lijn doet initiële analyse en onderzoek. Als de oplossing niet wordt gevonden, wordt deze geëscaleerd naar de tweede en derde lijn voor nauwkeurig onderzoek. Het incident wordt gekoppeld aan het relevante CI (configuratie-item) voor een snellere diagnose.
Incidenten Oplossen & Afsluiten
Incidentoplossing is cruciaal om aan de SLA te voldoen en daarom is tijdige oplossing belangrijk voor agents om goede prestaties te behalen. Efficiënte communicatie over de gevonden oplossing is net zo belangrijk voor gebruikers om weer aan de slag te kunnen zoals gebruikelijk. Het sluiten van tickets wordt automatisch door het systeem of via het selfserviceportaal afgehandeld.


